Be Readable
Readable is an online toolkit that helps writers everywhere improve their readability and bring their audience closer.
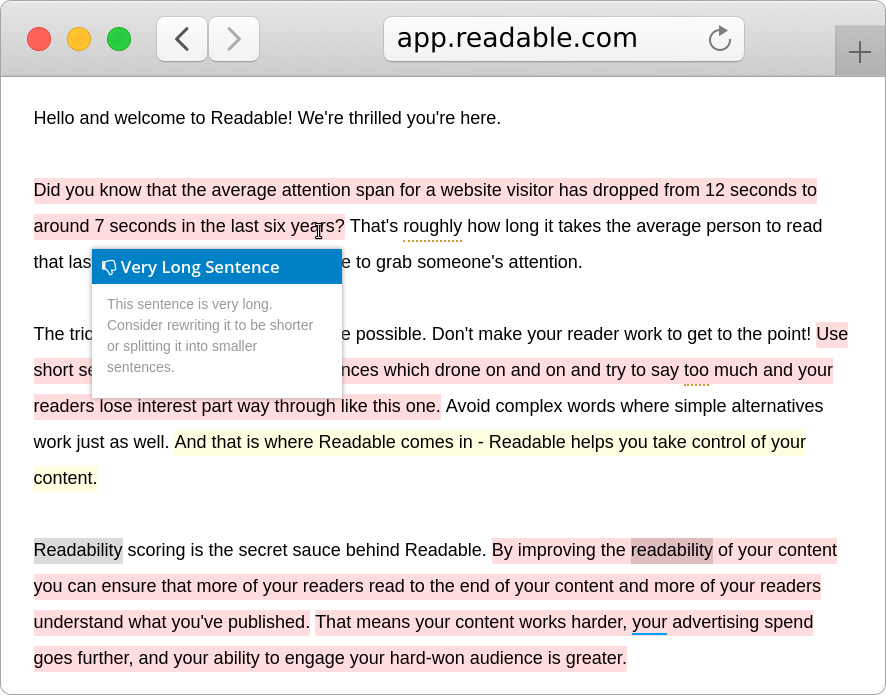
Your readability toolkit
Powerful, flexible readability tools that work where you work.
Unrivalled Readability Scores
Find the most accurate scores for formulas such as Flesch-Kincaid and SMOG, as well as our own bespoke readability algorithm.
Actionable Insight
Readable is packed full of features you won't find anywhere else. Hone your content for clarity and engagement to captivate your audience.
For Everyone
Whoever your audience or whatever your medium, Readable's user-friendly editor is suitable for all kinds of writers.
3,000+ authors, marketers, and educators trust us to deliver accurate readability analysis.







Discover the Power of Readability
Be understood
Grow your audience with clear, readable content.
85% of people can understand your content if it is a Readable grade A.
Make an impact
Attract new customers with crisp, dynamic content.
57% of customers are more likely to recommend you if they feel emotionally connected to your brand.
Build loyalty
Retain customers with direct, trustworthy content.
Readability builds customer trust. 81% of consumers said trust is essential in a buying decision.
Readability Tools
Document Readability
Improve your document readability and connect with your readers.
ContentPro helps you to produce clear, compelling content, helping you to engage with your audience.
Website Readability
Improve your website readability and lift conversions.
CommercePro is a suite of tools with a unique algorithm. The results give you actionable steps to optimise your website for readability.
Readability API
Integrate readability into your workflow and increase efficiency.
The Readability API on AgencyPro easily integrates into your website, CMS, product or service. Bring quality readability scores into your business.
What our happy customers say

Anna Bolton
Founder
Conversion Copy Co.
I use Readable to match my copy with my audience's reading level.
It's one of my top conversion optimization tools! ![]()

Candi Williams
Content Strategist
Nationwide Digital
Fact: good readability is good for everyone.
What Readable does is make it measurable. It makes readability tangible and gives the entire organisation something they can gather around. ![]()
Our promise to you
We are dedicated to providing the most comprehensive readability tools.
Accurate. Our scores are backed up by established readability algorithms and verified by over 10,000 automated tests and hand-calculated scores. You can be confident in your results.
Fresh. Our leading-edge readability checker is up to date with changes in standards. You can be sure your feedback is current and reflects real-world reading behaviour.
Here for you. We support your writing goals with our helpful resources and outstanding customer service.
Who's Readable for?
People and companies who want to make their content easy to read and understand.
Readable is used across all sectors and professions by people who value clarity and transparency in their business practice.
What is a readability score?
A readability score can tell you the level of education someone needs to easily read a piece of text. The score identifies a Grade Level relative to the number of years of education a person has. Read more about readability scores.
What is readability?
Readability is a measure of how easy a piece of text is to read. Read more about readability.
What is a good readability Score?
A Grade Level of 8 or lower is good for text aimed at the public. 85% of the public will be able to read and understand your content at Grade Level 8. Read more about readability scores.
Readability Formulas
The Readability Formulas that Power Readable
Latest from the Blog

How to use emotive language
Emotive language goes beyond simply stating facts. It taps into our emotional reserves. Specific words and techniques trigger joy, sadness, anger, and fear.
16 April 2024 by
The unofficial English of Europe: what is ‘Euro English’?
English continues to thrive as the unofficial language of Europe. It's evolving into its unique form: Euro English. Euro English is a dynamic lingua franca. It constantly adapts to the needs of its speakers.
29 March 2024 by
The fall of the semicolon: punctuation evolving
The semicolon – an enigmatic punctuation mark. It has long been a source of controversy. Researchers report a 25% decline in its use in British fiction over the past 30 years.
14 March 2024 by